
Before understanding Information Retrieval, it is essential to understand what information is. Information is simply processed data, which can be composed of text, images, audio, video, or multimedia objects. Structures and processed data are stored in Information Systems.
What is Information Retrieval?
Information Retrieval (IR) is the science and practice of finding information in a large repository, such as a digital database, library catalogue, or the internet, that is relevant to a user’s specific need or query. It involves the systematic organisation, storage, and searching of data to provide meaningful and useful results to users.
The term “Information Retrieval” was first introduced by Calvin Mooers in the 1950s. He defined it as the “searching and retrieval of information from storage according to a specific subject.” This definition emphasises the key role of subject-based searching – that is, the process of finding information that matches the topic or theme the user is interested in.
J.H. Shera extended this understanding by describing IR as “the process of locating and selecting data relevant to a given requirement.” His definition highlights two critical aspects of IR:
-
Location – The system must be able to search through large volumes of data.
-
Selection – It must also identify which information is relevant to the user’s query or need.
B.C. Vickery added another layer by focusing on the mechanisms involved. He stated that IR is “essentially concerned with the structure of the operation of the device to select documentary information from the store of information in response to several questions.” This points to the technical and operational aspects of IR systems – how they are designed to process user queries and retrieve appropriate documents or data.
Process of Information Retrieval-
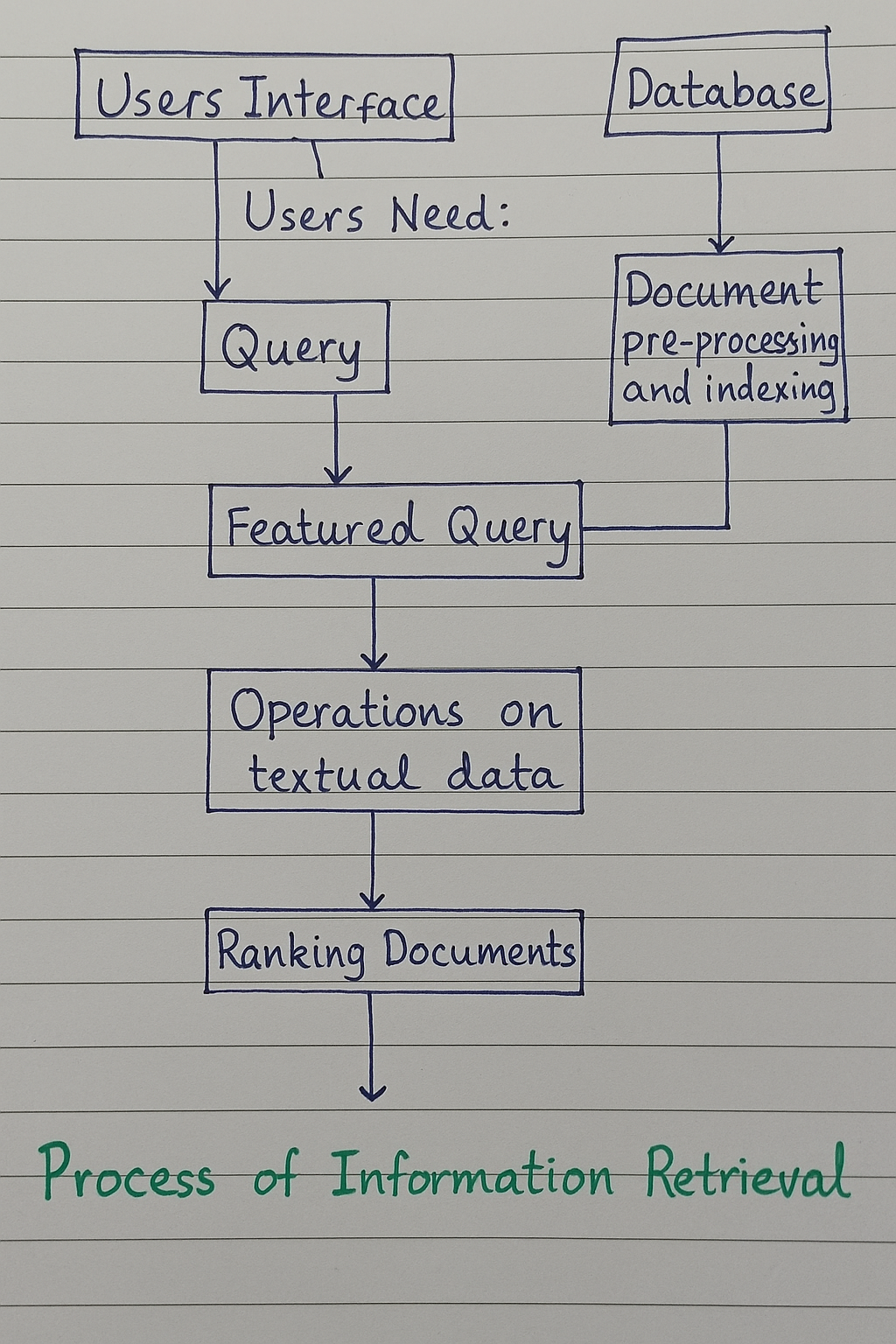 1.Users Interface
1.Users Interface
The process of information retrieval begins at the users interface, which serves as the point of interaction between the user and the system. This interface allows users to express their information needs, typically through a search bar or input field. It is the medium through which users communicate their requirements to the system in the form of queries.
2. Users Need → Query
Once a user enters their request, the system interprets this input as a query. This query reflects the user’s information need and is typically composed of keywords or natural language expressions. At this stage, the system’s role is to capture the intent of the user as accurately as possible in order to proceed with meaningful retrieval.
3. Query → Featured Query
The raw query is then processed and transformed into a featured query. This step includes refining and enhancing the input by applying techniques such as tokenization, stop-word removal, and term normalization. The aim here is to convert the user’s query into a structured form that can be effectively matched against the indexed documents in the database.
4. Database → Document Pre-processing and Indexing
On the database side, documents undergo a parallel process before they can be retrieved. This involves document pre-processing and indexing. During pre-processing, documents are cleaned, normalized, and sometimes enriched with metadata. Indexing then organizes these documents to facilitate efficient and fast searching. This step is essential for reducing the time complexity of matching queries with relevant content.
5. Featured Query + Indexed Documents → Operations on Textual Data
The featured query is matched against the indexed documents through various operations on textual data. These operations may involve similarity computations, matching algorithms, or relevance models. At this point, the system analyzes how closely the documents in the database align with the user’s featured query using computational models.
6. Operations on Textual Data → Ranking Documents
Once potential matches are identified, the system ranks the documents based on their relevance to the query. This ranking process is crucial for presenting the most useful results to the user at the top of the list. Relevance scores are calculated using various techniques such as TF-IDF, cosine similarity, or more advanced models like BM25 and neural networks.
7. Process of Information Retrieval
The final step of the process involves presenting the ranked documents to the user. This completes the cycle of information retrieval, where a user’s need is translated into a query, matched against a prepared database, and returned as a list of ranked documents. The entire process is designed to minimize user effort while maximizing the relevance and usefulness of the retrieved information
Core Components of an IR System-
To understand how IR works, it’s helpful to break it down into key components. Each one plays a unique role in transforming raw text into meaningful search results:
1. Document Collection
This is the corpus of documents collection the system can search through. Examples are- A digital library of academic articles, A collection of product descriptions on an e-commerce site and Billions of webpages indexed by a search engine, etc.
2. Text Processing

- Document
The text processing pipeline begins with the input document. This document could be in various formats such as plain text, HTML, PDF, or Word, and it contains raw, unprocessed content that may include punctuation, formatting tags, and natural language text. This raw document is the foundational unit that will be prepared for further analysis and retrieval tasks.
- Document Parsing
The next step is document parsing, where the structure of the document is analyzed to extract meaningful textual components. This may involve removing formatting tags, identifying and separating metadata from the content, and isolating sections such as headings, paragraphs, and tables. The main goal is to convert the raw document into a structured text format suitable for further processing.
- Lexical Analysis
Once the document is parsed, lexical analysis is carried out. In this step, the text is broken down into smaller units such as words, phrases, or tokens. Tokenization is a common technique used during lexical analysis to identify boundaries between words, punctuation, and symbols. This step transforms the unstructured text into manageable pieces for further linguistic and statistical processing.
- Stopword Removal
After tokenization, the system removes stopwords from the text. Stopwords are commonly used words such as “the”, “is”, “in”, “and”, which usually do not carry significant meaning for retrieval purposes. Eliminating these words helps reduce noise in the data and ensures that only the most meaningful terms are retained for indexing and analysis.
- Stemming and Lemmatization
The reduced set of tokens then undergoes stemming and lemmatization. Stemming reduces words to their root form by removing suffixes (e.g., “running” becomes “run”), while lemmatization converts words to their base or dictionary form considering the context (e.g., “better” becomes “good”). This step ensures that different grammatical forms of a word are treated as equivalent during retrieval.
- Weighing
Finally, the processed terms are assigned weights based on their importance within the document and across the document collection. Common weighting schemes like Term Frequency-Inverse Document Frequency (TF-IDF) are used to calculate the significance of each term. This weighting plays a critical role in determining the relevance of documents to user queries in the information retrieval process.
3. Indexing
To avoid scanning each document individually during a search, information retrieval (IR) systems build an inverted index. This index functions as a large lookup table, where each term is mapped to the list of documents in which it appears. For example, if a user wants to find all documents that mention the word “agriculture,” the system simply refers to the inverted index to retrieve the corresponding documents, rather than reading through every document anew. This greatly enhances search efficiency and scalability.
4. Query Processing
When a user submits a search query, the system processes it in the same way it processes documents during indexing. The query undergoes tokenization, stopword removal, and stemming or lemmatization to standardize its format. This preprocessing ensures that the query terms are comparable to those already stored in the index, enabling accurate and fair matching between the query and the documents in the system.
5. Matching
After processing the query, the system identifies relevant documents using various retrieval models. The Boolean model uses logical operators (AND, OR, NOT) to strictly include or exclude documents based on the presence of terms. The probabilistic model ranks documents by estimating the probability that a document is relevant to the given query, based on past data or assumptions. The vector space model represents both documents and queries as vectors in a multi-dimensional space and computes their similarity—typically using cosine similarity—to retrieve and rank results accordingly..
6. Ranking
Once relevant documents have been identified, the next step is to rank them according to their relevance to the user’s query. This is achieved through scoring algorithms that assign a numerical value to each document based on its similarity to the processed query. Higher scores indicate greater relevance, allowing the system to present the most pertinent documents at the top of the results list. Ranking ensures that users receive the most useful and contextually appropriate information first.
7. Retrieval & Feedback
Finally, the top-ranked results are shown to the user. In modern systems, feedback such as click behavior or user ratings can be used to improve future searches.
